今天分享的是Roberto Perdisci教授在2013年发表在ESORICS上的一篇论文,该文在Google学术中虽然引用不高,单独读完之后感觉在分类前提取特征的方法写得不错,分享给大家。
概述
论文主要观点:
通过在网络出口部署相关设备,可以观察局域网内所有软件下载行为,通过一系列的行为特征和恶意软件的标签即可实现恶意软件的分类,并且可以发现未知恶意软件,同时该分类效果比谷歌浏览器的恶意检测系统在一定程度上误报率要低。
论文主要成果:
- 提出了一种在网络数据包中检测恶意软件下载行为的模型;
- 通过实际部署发现效果还不错,可以发现一些未知的恶意样本;
- 通过对比发现,模型的误报率其实挺低,准确率也挺高的。
模型框图
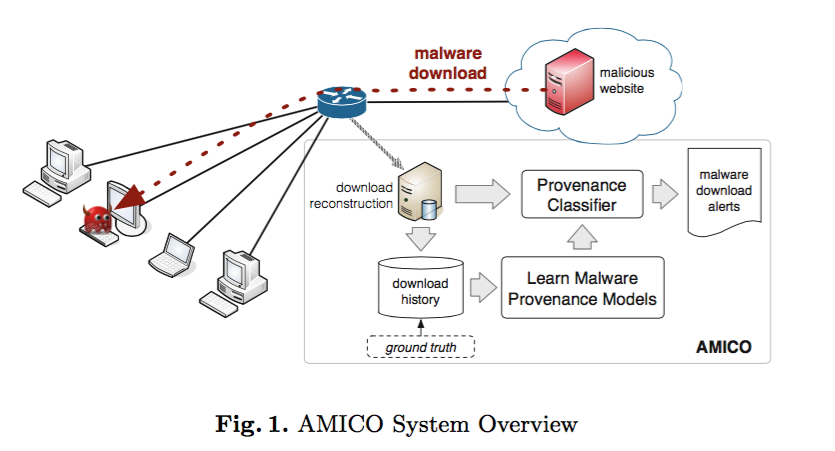
创新技术点
个人感觉论文主要的亮点在于对这种检测模型中的特征的挖掘和阐述,其次文章对模型和整个研究内容的细节和死角都做了很详细的分析和阐述,让你找不出破绽。另外作者的测试方法也还是蛮有意思的。
这里重点阐述作者模型中的特征选取问题:
历史下载数据。
通过分析连续一段时间文件的下载次数,多少客户下载,第一次下载是多少天以前,一天有多少下载量等,这个作为一个大类的特征,然后分为很多小特征。
「选择依据」一个正常软件的sha1值一般是固定的,因为一般软件升级需要一段时间,而恶意软件则需要经常免杀,所以sha1值经常变动,导致每个sha1值的下载量很少,并且恶意软件下载的量一般也会很少。
域名特征
主要涉及域名的二级域名,或者域名后缀,同时结合历史数据来计算每一类域名的恶意概率,正常文件对应的数量,每个顶级域名下载量等。
「选择依据」恶意软件虽然经常变换域名,但是很多时候可能只是更换二级域名或者是直接更换定于域名,但是一般情况下后缀不会改变,另外恶意域名对应的下载量应该很小,应该会经常变换域名和文件。
服务端IP特征
涉及服务端IP所属BGP,服务器地区,然后跟这几个属性关联的数量,比如某个BGP下下载量是多少,有多少正常文件等等。
「选择依据」恶意文件托管或者存放一般可能会改动IP地址,但是改动不大,可能还是一些BGP下,那么统计其分布情况和数量就非常重要。
URL特征
主要考虑URL的构成(路径,特殊符号,参数,文件名等)跟恶意数量和正常样本的数量分布情况,
「选择依据」考虑一个团伙或者一套恶意系统往往存在一些相似的地方,其URL相似度可能比较高。
下载请求特征
恶意软件下载的时候请求头,是否带有referer url,路径的深度等于历史。
「选择依据」很多恶意请求基本上referer都是为空,另外恶意文件下载的链接跟正常的一般也不一样,没有jpg,gif这些后缀。
缺点
- 虽然作者考虑了很多因素来综合评定文件是否恶意,但是HTTPS没办法测试,除了SSLtrip。
- 针对分段的恶意木马没办法检测;
- 恶意攻击者可以针对性改进。
后话,作者主页上的Useful Public Resources对恶意库和检测平台总结还是比较全,推荐。